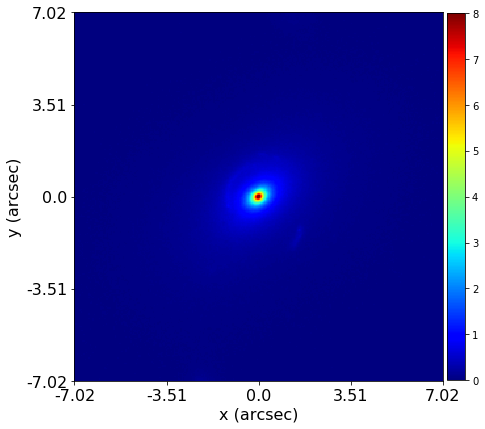
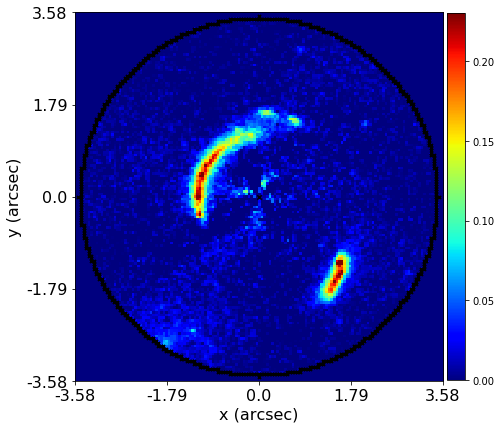
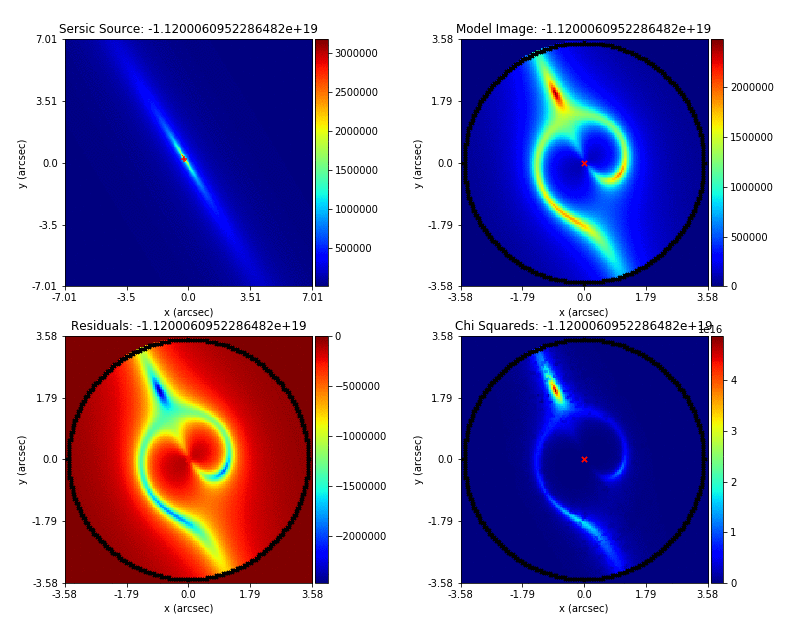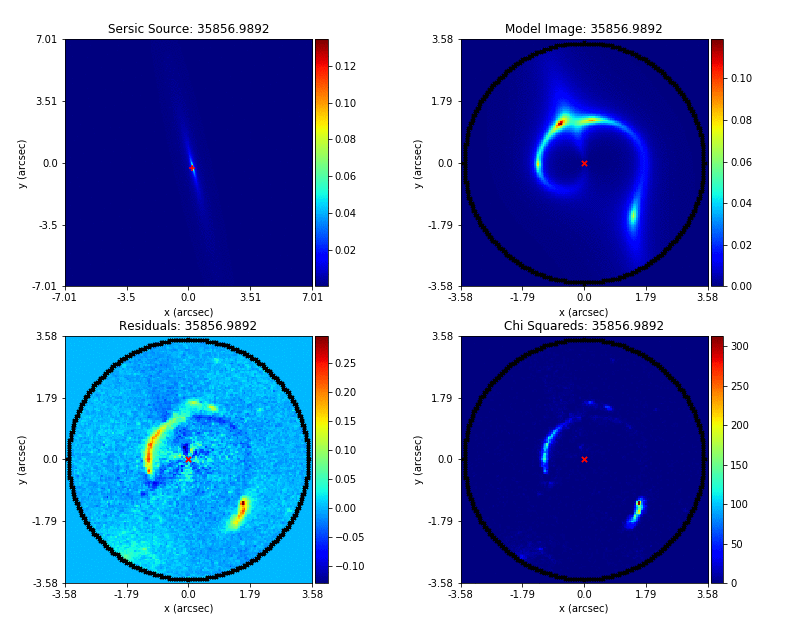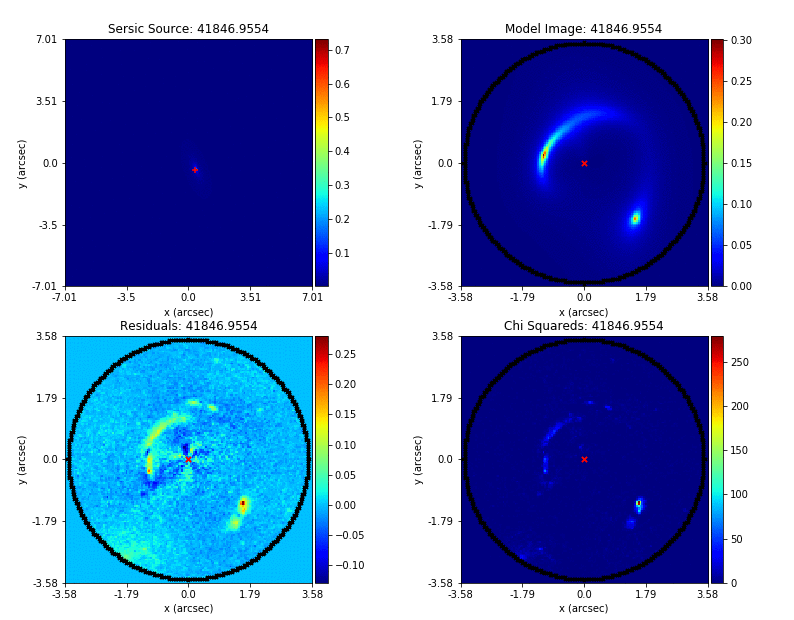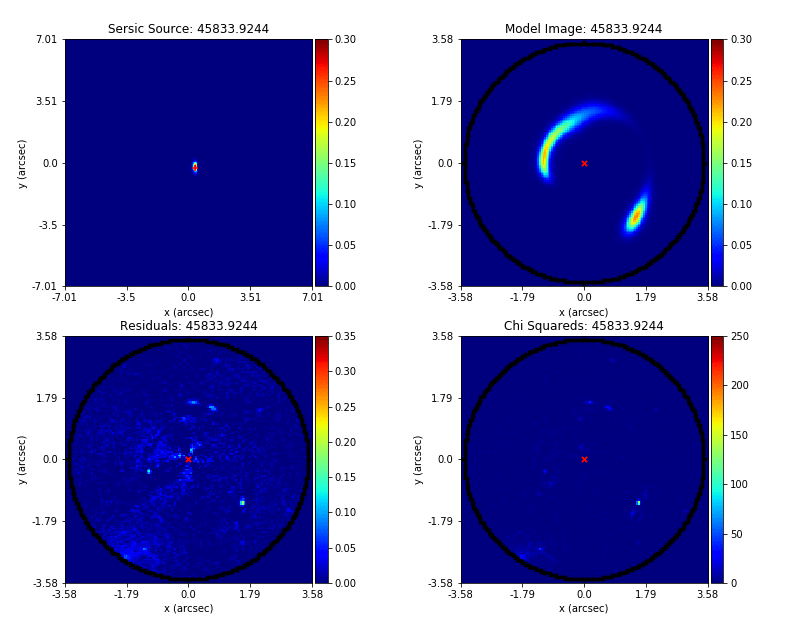
@jax.jit
def w_tilde_curvature_interferometer_from(
noise_map_real: np.ndarray[tuple[int], np.float64],
uv_wavelengths: np.ndarray[tuple[int, int], np.float64],
grid_radians_slim: np.ndarray[tuple[int, int], np.float64],
) -> np.ndarray[tuple[int, int], np.float64]:
# (M, M, 1, 2)
g_ij = grid_radians_slim.reshape(-1, 1, 1, 2) - grid_radians_slim.reshape(1, -1, 1, 2)
# (1, 1, K, 2)
u_k = uv_wavelengths.reshape(1, 1, -1, 2)
return (
jnp.cos(
(2.0 * jnp.pi) *
# (M, M, K)
(
g_ij[:, :, :, 0] * u_k[:, :, :, 1] +
g_ij[:, :, :, 1] * u_k[:, :, :, 0]
)
) /
# (1, 1, K)
jnp.square(noise_map_real).reshape(1, 1, -1)
).sum(2) # sum over k